ML算法概述
此处相暂时不讨论有关概念、名词,而是通过一场云课堂迅速了解有关机器学习的一些基本概念,为后续学习留下基本印象。
三、算法分类
监督学习
分类预测
- 根据数据样本上抽取出的特征,判定其属于有限个类别中的哪一个。
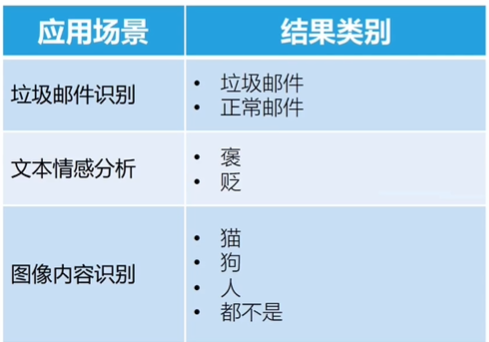
回归分析
- ,预测连续值的结果。
- 如电影票房值;某城市房价的具体值。
无监督学习
聚类
关联规则
强化学习
- Q-learning
- 时间差学习
四、ML模型评估与选择
——以房产价格预测为例
4.1经验误差、过拟合
经验误差,指的是模型在训练集上的误差,empirical error:
- 即参考答案与预估结果的差值平方,再平均,作为概述的经验误差。
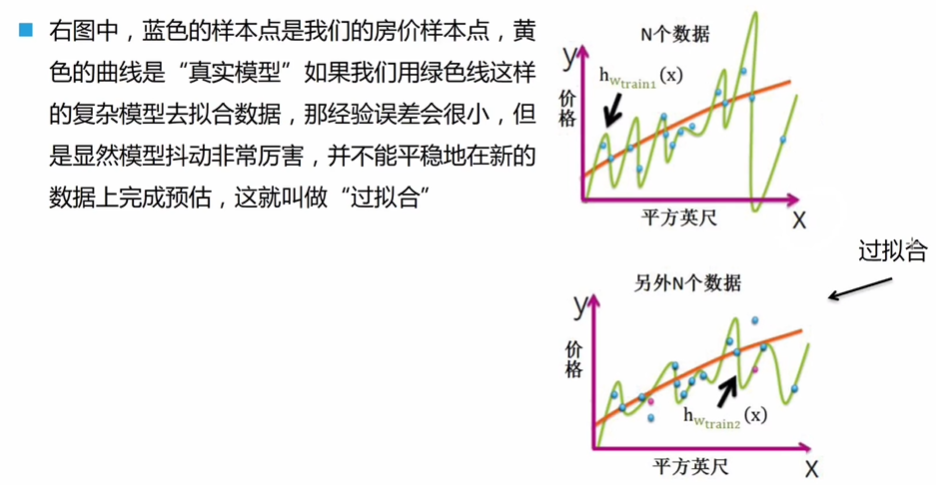
- 训练好的模型,需要在测试数据、真实环境中平稳地完成预估。否则就是过拟合
4.2偏差与方差
例如,用平均价格(这是极其简单的模型)来预估,显然其偏差十分大:
- 这里的平均价格模型简单、抖动小,但是学习能力极差。
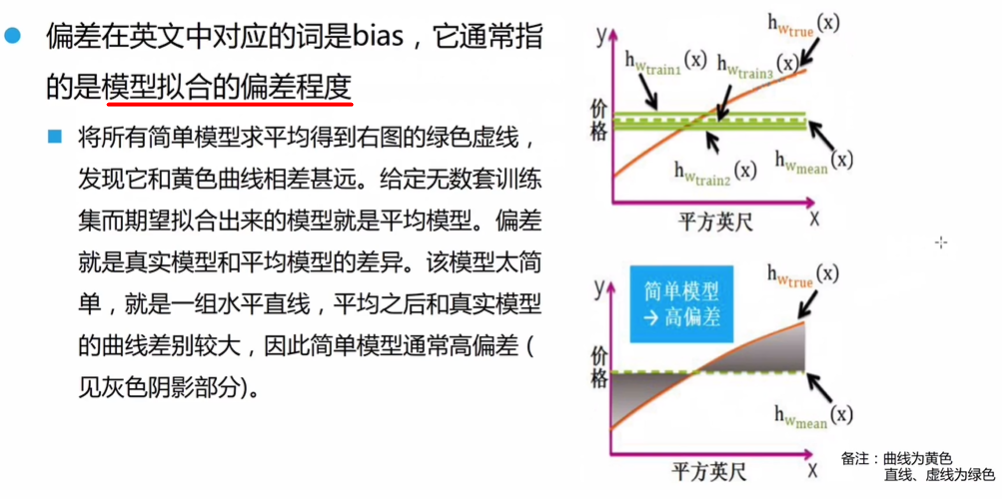
- 这里的平均价格模型简单、抖动小,但是学习能力极差。
例如,复杂模型的偏差:
- 会小,因为平均后最大值和最小值会相互抵消。
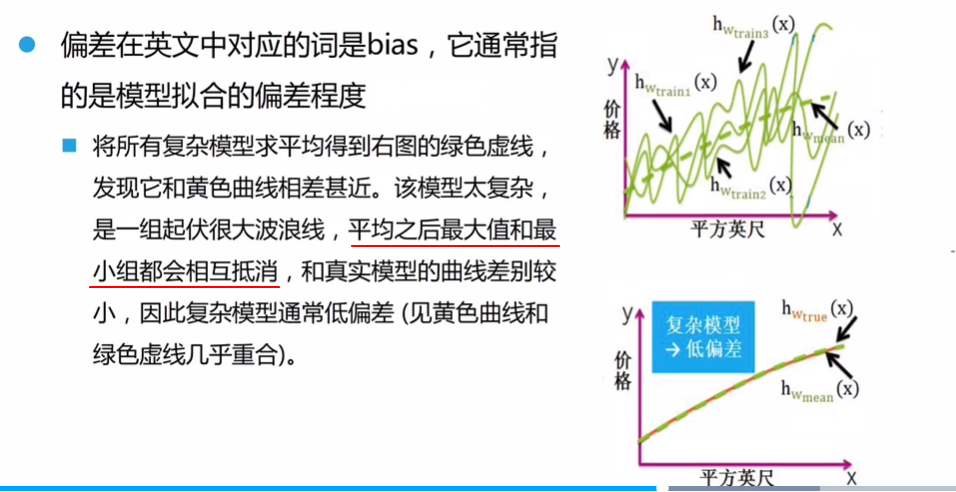
- 会小,因为平均后最大值和最小值会相互抵消。
方差同理:
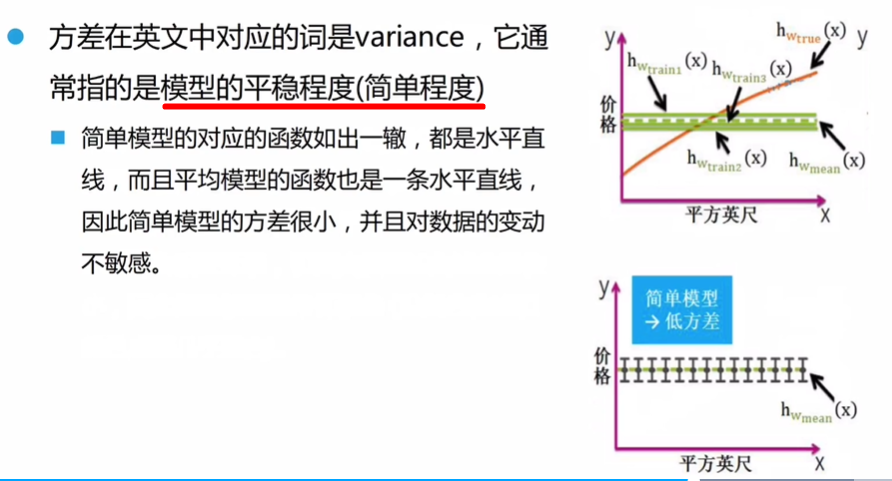
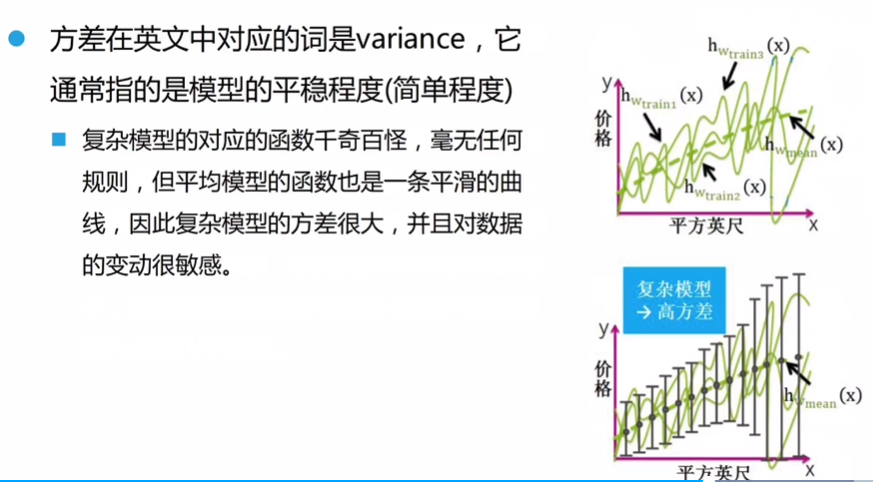
复杂模型一般具有:较低的偏差,较高的方差
简单模型一般具有:较高的偏差,较低的方差
简单模型“欠拟合”,复杂模型“过拟合”
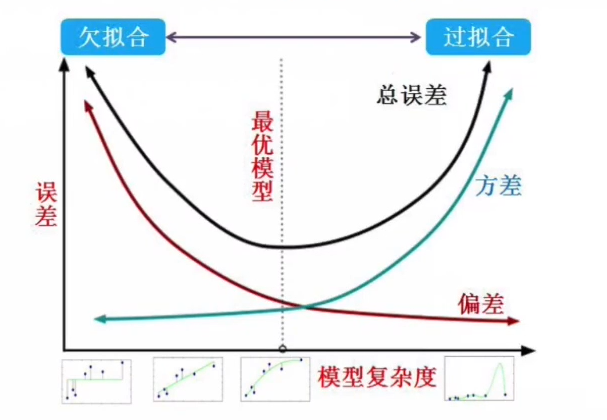
4.3性能度量指标
分类问题的常用性能度量方法:


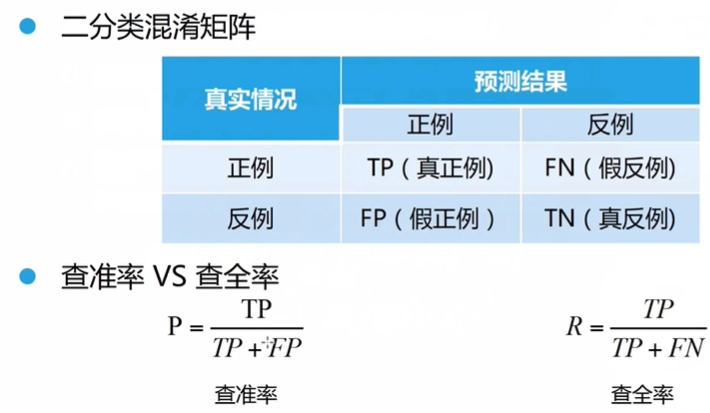

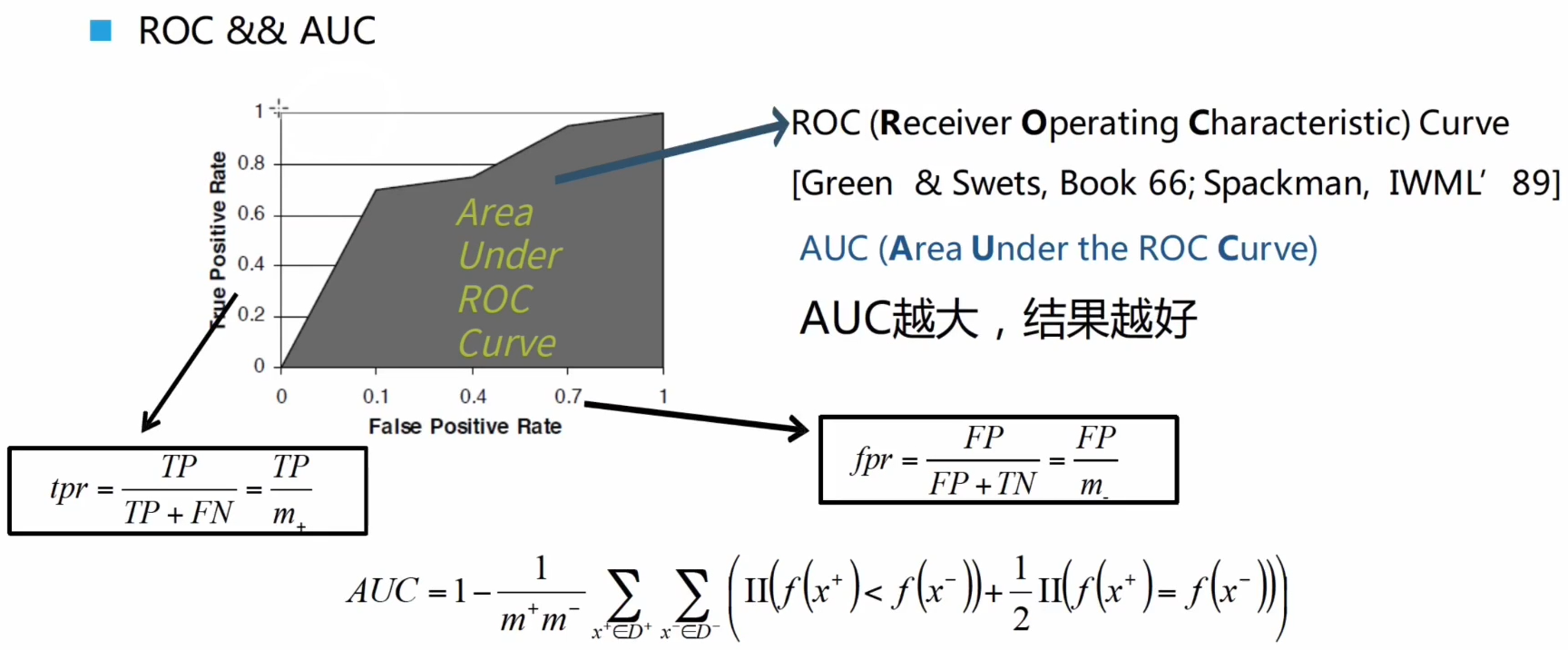
- AUC一般为度量排序的指标,一般在排序,或者样本分布不均衡的问题中被采用,
- 一般取值在0.5-1
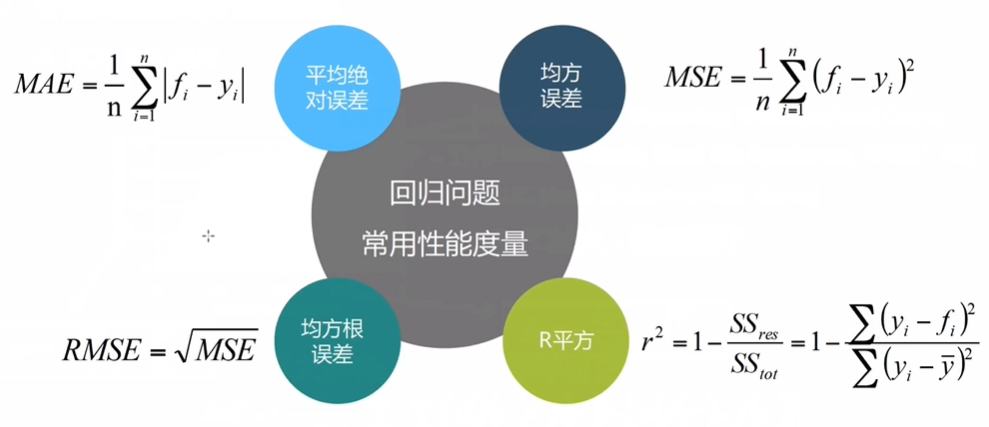
回归问题的性能度量:
4.4评估方法
解决手上没有未知的样本,如何进行可靠的评估?
留出法 hold-out
- 例如,电商数据中,男女比例、地区分布一致。
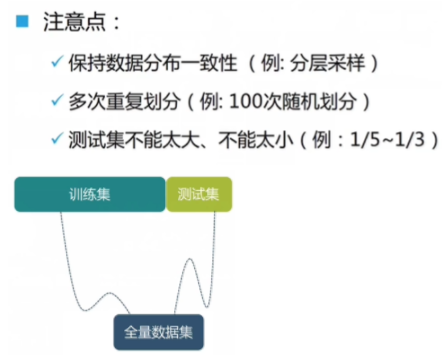
- 例如,电商数据中,男女比例、地区分布一致。
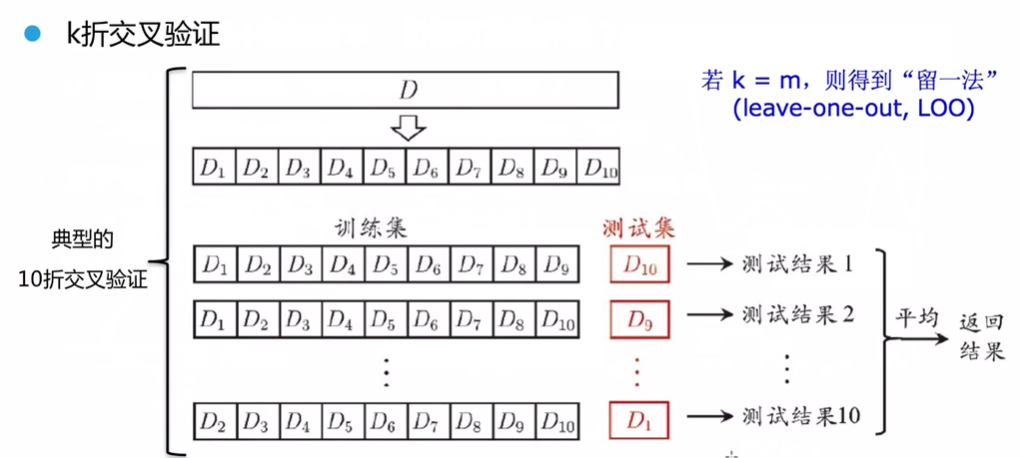
交叉验证法 cross validation
自助法 bootstrap
- 可能会改变数据的分布,因为被放回了就会可能被重复抽取到。
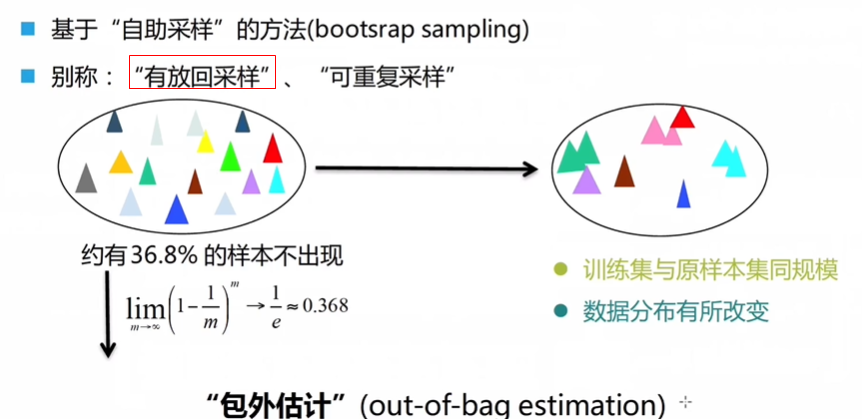
- 可能会改变数据的分布,因为被放回了就会可能被重复抽取到。
4.5选择最优的模型

reference
ML算法概述
https://youdef.com/posts/31/