算法基础篇2
提纲:本篇希望了解二分查找、跳表、散列表。
15二分查找
Binary Search是一种针对有序数据集合的查找算法。我们常折半思想来猜数字。设查找k次找到该值,即
$$
\frac{n}{2^k} =1 \
k = logn
$$
- 依赖于数组(顺序表结构)
- 数据需有序
- 数据量不大不小的情况下,毕竟数组需要连续的内存空间。
找中值:
1 | |
简单情况下的二分查找
即,当有序数组中不存在重复元素
1 | |
1 | |
问题
1 | |
复杂二分查找(存在重复数据)
引言
作者列举了如何查找IP地址对应省份,但我不是很看懂。
变形1:查找第1个值等于给定值的元素
1 | |
变形2:查找最后1个值等于给定值的元素
1 | |
变形3:查找第一个大于等于给定值的元素
1 | |
变形4:查找最后一个小于等于给定值的元素
1 | |
跳表
问题:为何Redis使用跳表实现有序集合。
分析:跳表与红黑树有相似之处,但更为简单。Redis中的有序集合支持的主要操作有:
- 插入一个数据
- 删除一个数据
- 查找
- 按照区间查找数据
- 迭代输出有序序列
我虽然没有学过Redis及其实现,但基于上面的需求,跳表的插删查操作的时间复杂度都在$$ O(logn) $$ 量级上,具备一定优势。对于按照区间查找数据操作,由于跳表使用链表实现原始数据存储,在找到起点数据后向后遍历即可。而红黑树作为树,在众多分叉中较难遍历区间。
最后,跳表较为灵活,可以通过改变索引构建策略,找到执行效率、内存消耗之间的平衡。
跳表,是一种基于链表的”二分查找“的动态数据结构,在原始数据基础上建立多组索引达到加快查找的目的,能有效弥补链表天生查找效率低的情况。
具体操作是,从原始数据链表开始,每m个结点抽取1个结点到上级索引,依次向上组成k级索引。
这里的动态性,我觉得是在插入、删除数据时,为维护整个索引的稳定,需要不断调整整个索引层。也就是,在插入数据时,需要先查找到数据应该插入的位置,再执行链表元素插入;在删除原始链表中数据时,需要找到该元素的前驱结点。此外,大量的插入、删除肯定会改变原始数据的面貌,可能某个删除的数据在索引层中也出现了,为此,索引层也需要调整。(见下图示例)
- 明确增加索引的层数,可以减少索引比较查找的次数的;

索引的动态更新:
即维护索引与原始链表之间的平衡,这里被介绍了“随机函数”方法。
- 维护的平衡是,避免过度集中插入,使跳表倒退成单链表;
- 随机函数决定将插入的结点插入拿几级结点中,如随机函数生成值为s,将插入的值插入原始链表、1-s级索引中。
理解是这样,如何实现又是一门实践编程的学问了。

跳表的时间复杂度:
不做详细描述,第k级索引的结点:(设最高索引2个结点)
$$
\begin{equation}
\frac{n}{2 * 2^{k-1}}=\frac{n}{2^{k}}令=2 \
有k = logn-1, 即高度
\end{equation}
$$
时间复杂度为$ O(m*logn) $ ,m=3,表示每层至多要遍历3个结点。
跳表的空间复杂度:
从2个结点抽取1个结点,k个索引结点个数之和:
$$
\begin{align}
n/2+n/4+n/8+…+8+4+2 = n-2 \label{eq2}
\end{align}
$$对从3个结点抽取1个结点,k个索引结点个数之和= n/2
由此可以看出,通过调整抽取基数m可以减少索引需要的结点。
散列表
Word中单词拼写检查是如何实现的?
答:1个字母为1字节,20万单词约为2MB,足够存入散列表;将字典中的全部单词存入散列表可以按照一定的散列规则来,这样在对用户文档做拼写检查时,以单词为key值找到散列表中是否有该单词。
字母的值作“进位相加” 再求余、取模:
1 | |
散列表在数组支持下按下标随机访问,将元素键值映射为下标。例如将学生学号映射为散列表中存储的score信息。
1 | |
常见的MD5、SHA、CRC等哈希算法也存在散列冲突的可能。
散列冲突解法1:开放寻址
使用hash(key)查找到地址已经有数据之时,需要重新探测地址。
- 线性探测:该位置已有数据,则+1继续查看是否有数据,没有则存入数据
- 二次探测:$hash(key) + 0, 1^2, 2^2,…$
- 双重散列:设计一组散列函数,如果计算得到的存储位置已被占用,再用第二个散列函数。
如何表示空闲情况:装载因子:load_facot = 填入表中的个数 / 散列表长度
散列冲突解法2:链表法
hash(key)指向某bucket/slot,每个桶/槽对应一条链表。理解:散列函数计算出的相同值的元素被存储到相同位置的链表中。
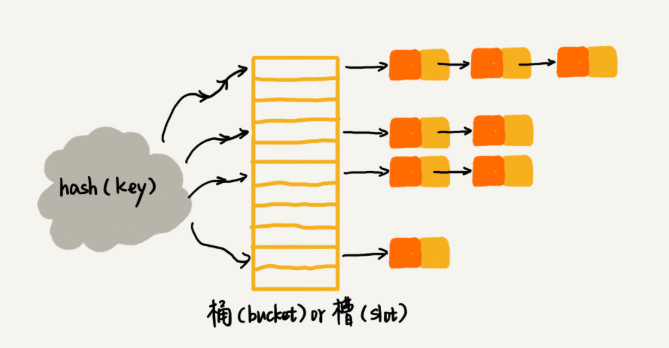
避免散列表碰撞攻击
散列表碰撞攻击指 恶意攻击将所有的数据存储到同一个槽里的链表中,这样散列表被退化为链表,查找的复杂度变为O(n)。
散列函数设计要求简单,减少服务器消耗;散列函数生成的值应该尽量随机分布。
- 数据分析法:分析手机号码可知手机号前几位相似情况很多,可以取后4位作key;
- 前面提到的。对单词中的字母进位相加,再与散列表的大小求余、取模
装载因子过大后:散列表扩容:
散列表使用函数计算出存储位置因此扩容时需要重新计算位置。除了“一次性”扩容,我们可以选择扩容后穿插插入:1.已满的散列表不动;2.申请2倍大小的新散列表,将新产生的数据存入,旧数据慢慢存入。
解决散列冲突方法的优劣:
- 开放寻址易于序列化,但是删除数据需要标记已删的;
- 适用于数据量小,装载因子小时,如ThreadLocalMap
- 链表法
- 链表耗费内存,对内存不友好。为此可将链表转换为树、跳表
- 基于链表的散列冲突处理方法适用于存大对象、大数据量的散列表,比开放寻址法灵活,有优化空间。例如LinkedHahMap
举个栗子:
HahMap默认设置散列表大小为16,装载因子为0.75,超过后自动扩容2倍。链表长度大于8时,将链表变为红黑树。
1 | |
散列表的设计应该满足几点:
- 支持快速地查询、插入、删除操作;
- 占用内存合理;
- 性能稳定,在特定约束条件下不会退化到无法接受的情况。
散列表需注意:
- 设计合适的散列函数;
- 定义转载因子阈值、动态扩容策略;
- 散列冲突解决方法。
例子
LRU缓存淘汰算法
用链表复杂度为O(n),散列表+双向链表O(1)。
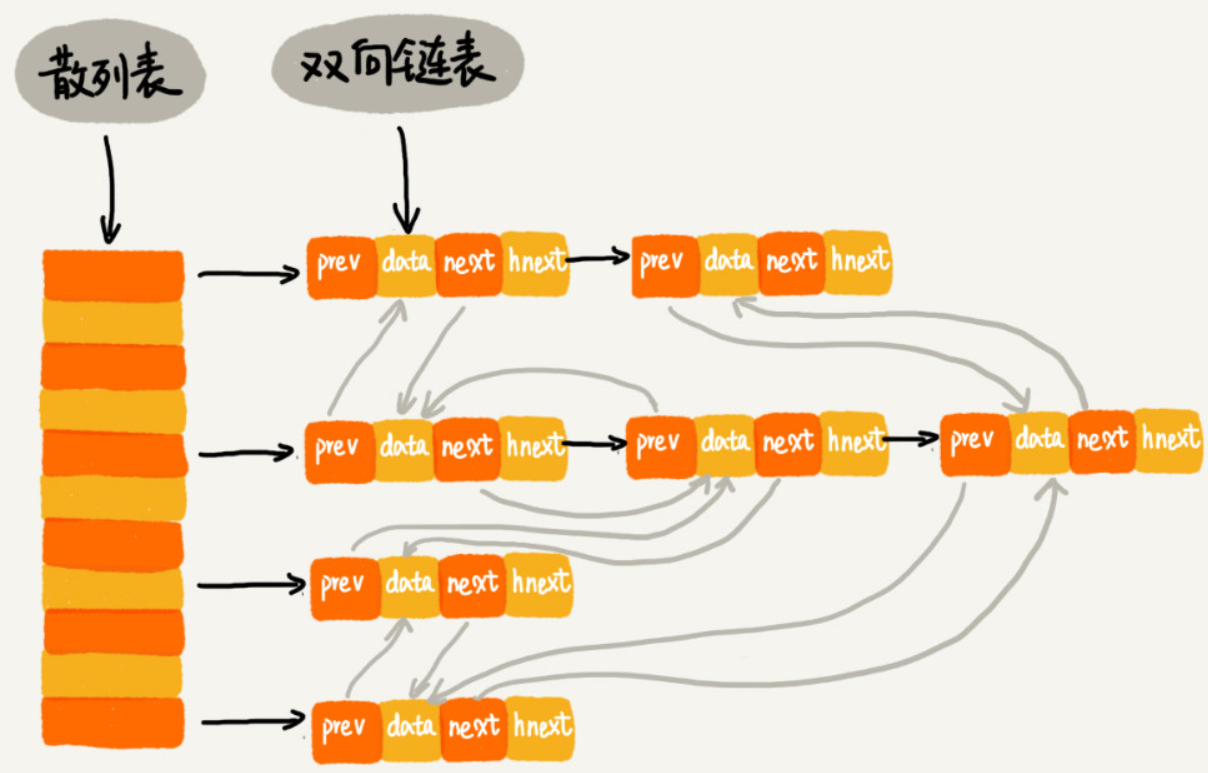
其前驱、后继指针将结点串在双向链表中;hnext指针将结点串在散列表的拉链中。
当添加一个数据时:
查看该数据是否在缓存中;
若在缓存中,将其移至双链表尾
若不在,
- 缓存满了:将双链表头部结点删除,数据放链尾;
- 缓存未满:数据放链尾;
注意:这里的新访问的数据放链尾或联头,应该都是可以的,只有逻辑关系在。
Redis有序集合
LinkedHashMap
如何做到按照顺序遍历,也可以按照访问顺序遍历。
因为,散列表中的数据是打乱后无规律存储的,无法按照其他某些顺序遍历。
所以,使用Hash表 + 双链表/跳表。
21哈希算法
问题:如何防止数据库被脱库?
回答: